Machine learning (ML) neboli strojové učení je poslední dobou velmi používané slovní spojení, které v sobě obsahuje vše od zpracování dat až po neuronové sítě. V tomto článku vám představím základní terminologii a na krátkém příkladu ukážu klasifikaci filmových hodnocení a sentimentu v textu.
Učení s učitelem a bez učitele
Strojové učení se obecně dělí na dvě kategorie, a totiž na Supervised (s učitelem - systém se "učí" funkci z trénovacích dat) a Unsupervised (bez učitele - systém hledá zákonitosti v datech sám).
První kategorie je specifická tím, že vstupní data, která budeme analyzovat, mají dodatečné atributy, které data nějakým způsobem popisují. Příkladem mohou být údaje o teplotě ve městech za nějaký časový úsek, typickým příkladem v ML je však tzv.
MNIST dataset. Je to sada psaných číslic, jejichž atributem je právě odpovídající číslo na obrázku.
S daty můžeme dále provádět tzv. klasifikaci, nebo regresi. Klasifikace slouží ke správnému zařazení datových vzorků bez atributů (tedy např. rozpoznání nově napsané číslice a její správné označení, nebo níže v návodu - rozpoznání pozitivního a negativního filmového hodnocení z textu). Regrese slouží k "předpovídání" dalších výsledků, používá se např. pro generování textu - lze tak vygenerovat celou
novou kapitolu Harryho Pottera na základě předchozích 7 knih.

Příklad vzorků z datové sady MNIST
Druhou kategorií je učení bez učitele. Používá se pro neoznačená data bez atributů, nejčastěji pro nalezení skrytých vzorců a spojení mezi datovými vzorky nebo pro jejich setřídění do skupin (tzv. clustering).
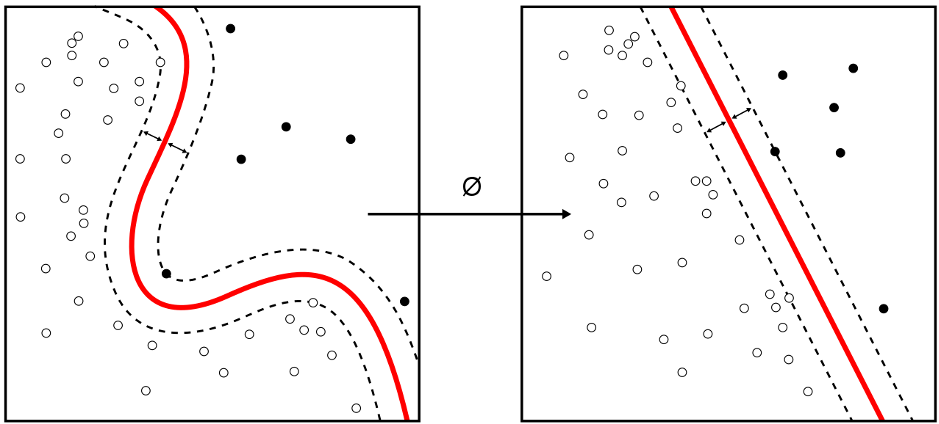
Učení bez učitele -
určení hranic mezi rozdílnými body, clustering
Datové sady, datasety
Datová sada (pro učení s učitelem) se dělí na tři části - trénovací, testovací a validační. Trénovací sada obsahuje hlavní data, na kterých se ML bude učit "vzorce chování", konfigurace datových vzorků a určovat váhu jednotlivých rozhodnutí pro konečný výsledek klasifikace/regrese. Validační datová sada je pak část disjunktní s trénovací sadou, avšak ze stejné množiny dat, resp. z dat se stejnou distribucí pravděpodobnosti (jinými slovy: z jedné datové sady psaných číslic vezmu náhodně 70 % vzorků pro trénovací sadu a 30 % pro validační). Poslední částí je ta testovací, která používá podobná data s odlišnou distribucí pravděpodobnosti - v případě datové sady psaných číslic, kde trénovací a validační sada byla psaná mnou, trénovací sada by byla psaná někým jiným - pro výsledný klasifikátor tak mohu určit jeho přesnost správného určování nově napsaných číslic, a jako takový slouží tato přesnost jako hlavní metrika určující kvalitu natrénovaného modelu.
A teď k praktickému příkladu
Jako malý příklad zde uvádím klasifikátor filmových hodnocení. K tomu jsem nejprve získal textová data ze serveru imdb.com, a to hodnocení k novému filmu "1917". Ručně jsem zkopíroval 20 pozitivních hodnocení a 20 negativních hodnocení filmu (v reálném projektu by se samozřejmě použilo IMDB API pro hromadné stažení dat) do jednoduchého textového souboru - prvních 20 řádků pozitivní hodnocení, dalších 20 řádků negativní. Reálná data jsou formátována sofistikovaněji, např. v csv formátu a s explicitně uvedenými třídami, ale pro názornost to zde postačí.
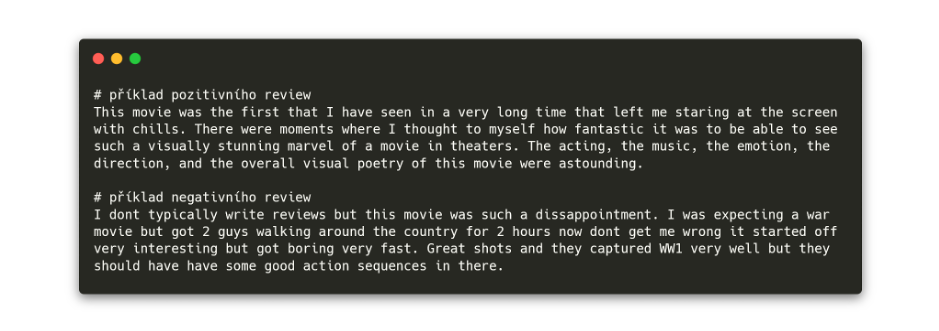
V Pythonu pak tento soubor "dataset.txt" načtu:

Nyní mám načtené všechny věty do pole hodnot. Dále text musím zpracovat, aby z něj mohl klasifikátor při tréninku úspěšně extrahovat smysluplné informace. Anglický text tedy zbavím apostrofů, znamének apod. a provedu lematizaci - tedy převedení slov do jejich kořenové podoby (movies -> movie, being -> be).

Takto zpracované věty teď musím nějakým způsobem převést do formátu zpracovatelného pomocí ML. Provedu proto vektorizaci slov - jejich převedení na číselnou hodnotu (tedy něco přibližně podobného získání počtu nejčastějších pozitivních slov, akorát s mnohem hlubším kontextem). K tomu použiji vektorizační metodu
Bag of words. Vektorizér nastavuji tak, aby bral pouze prvních 20 nejčastějších slov jako významných, používal ta slova, která se vyskytují alespoň dvakrát, a jsou nejvýše v 60 % hodnocení (jinak by ztratily svůj význam, kdyby byly používány všude). Navíc vyřazuji anglická "stop" slova, která nenesou žádný význam (and, the, ...).
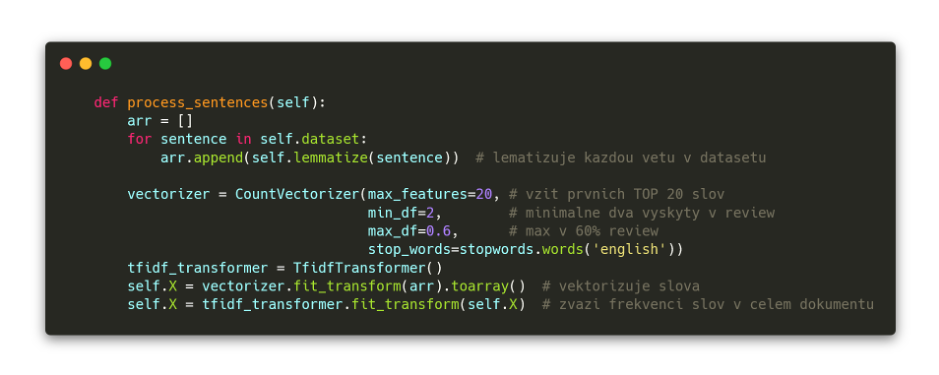
Po této transformaci pomocí vektorizace jsou vstupní textová data s hodnoceními filmů reprezentována čísly (každý řádek je jedno celé souvětí/hodnocení):
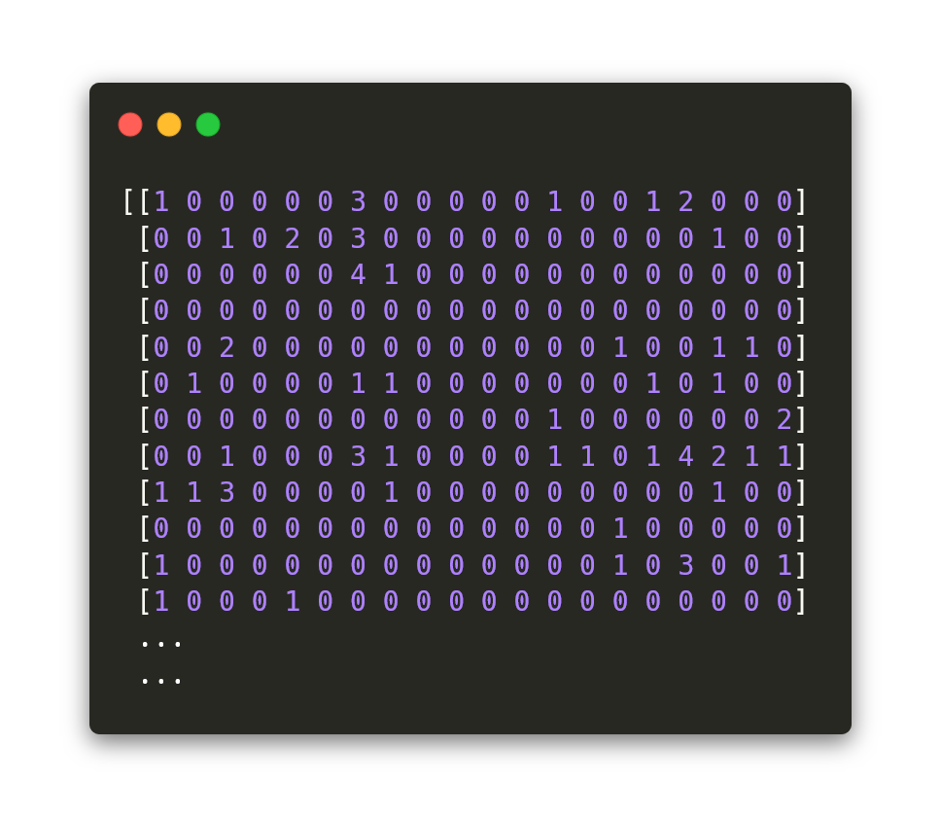
A teď se můžeme vrhnout na samotný trénink klasifikátoru. Používám zde jednoduchý klasifikátor,
K-nejbližších sousedů, s K-okolím velikosti 5 (na složitější klasifikátory a jejich hlubší popis se podíváme v příštím článku). Trénovací data jsem rozdělil na trénovací a testovací (beru 30 % datové sady pro testování).
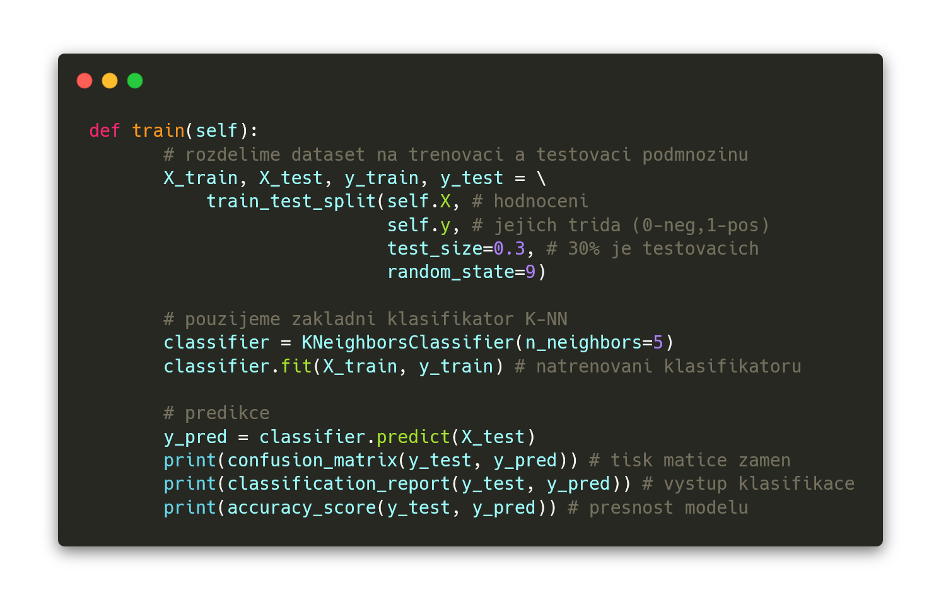
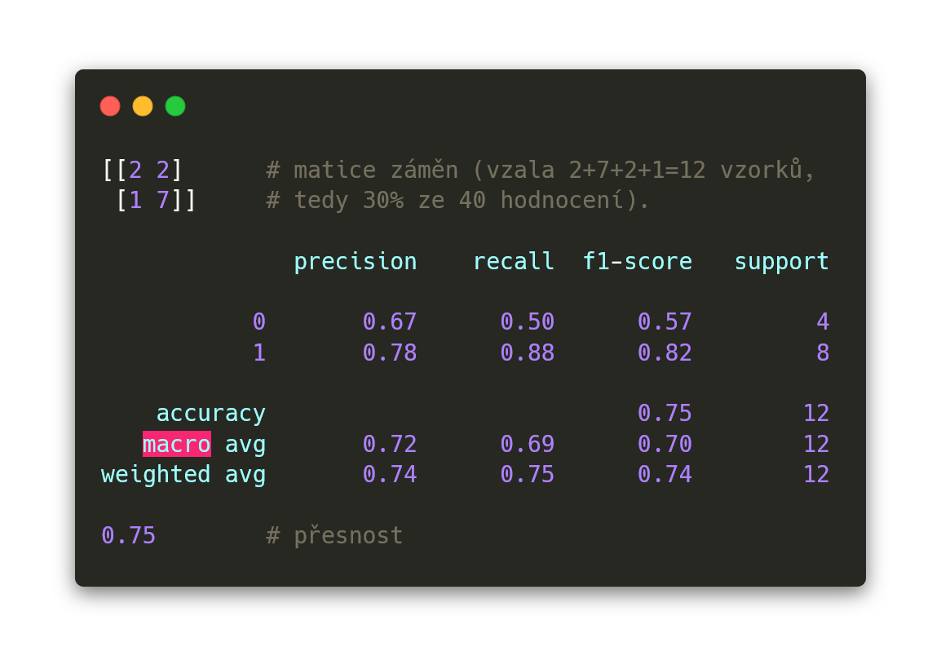
Nakonec probíhá tisk tzv. matice záměn, která ukazuje úspěšnost natrénovaného modelu klasifikátoru, výstupu klasifikace a hodnoty přesnosti našeho modelu.
Matice záměn ukazuje počet správně uhodnutých hodnocení na jedné diagonále a špatně uhodnutých na diagonále druhé - viz obrázek níže, tedy 2-7 je počet tzv. true positives a true negatives (tzn. správně uhodnutá hodnocení patřící do správné třídy a správně vyloučená hodnocení nepatřící do třídy) a 1-2 je počet false positives a false negatives, tyto chybné false hodnoty chceme udržet na minimu.
Bohužel zde používám jen extrémně malou datovou sadu, takže přesnost klasifikace je mizerná - jen 75 % hodnocení je zařazeno správně jako pozitivní nebo správně jako negativní, a to po úpravě parametrů pro lepší výsledek (v závislosti na parametrech klasifikátoru přesnost padala i na pouhých 35 %). Při zvětšení datové sady na několik tisíc hodnot a použití inteligentnějšího klasifikátoru by se přesnost značně zvýšila.
Analýza sentimentu v textu
Pro zajímavost ještě ukážu analýzu sentimentu z textových dat. Jedná se o NLP - Natural Language Processing (neplést s Neuro-linguistic programming), analýzu přirozeného jazyka, jejímž cílem je extrakce názorů a emočního zabarvení textu (datové sady bývají vzaty zejména z Twitteru). Sociální sítě jsou tedy přirozeně hlavním polem, kde se NLP využívá v praxi.
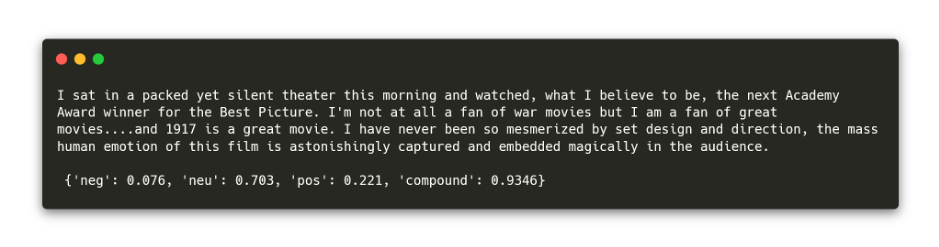
Pro příklad použiju VADER (Valence Aware Dictionary and sEntiment Reasoner) na jednom z filmových review. VADER dokáže analyzovat pozitivní nebo negativní sentiment v textu na základě předtrénovaného klasifikačního modelu (pro přesnější klasifikaci lze použít např. Google Cloud Natural Language API).

Výstup předchozích 3 řádků nám ukazuje ze 70 % neutrální sentiment a z 22 % pozitivní sentiment (jde o jedno z pozitivních hodnocení).
 Na závěr
Na závěr
Pokud vás datová analýza a strojové učení zaujalo, můžete začít u mého příkladu, který jsem umístil ve svojí celkové podobě na
github. Strojové učení má velkou škálu možných použití a nepřeberné množství algoritmů, kde se každý hodí pro jinou oblast. Na tyto algoritmy se podíváme příště, do té doby přeji happy machine learning!
Jan Jileček